How to Build a New Programming Language
Are you tired of just using programming languages for work, without knowing how it works? Do you want to know what’s happening inside the machine, after you’ve finished writing your code?
Well, you are not the only one. And you will know everything about it after reading this article.
As it turns out, there are three concepts, each extremely close to the others:
- How a programming language works, from the inside.
- How a Compiler works.
- How to build a new programming language.
Ultimately, I think the third point is what every curious student like us is interested in. So, we are in luck that these are all similar concepts!
How to build a new programming language
Let me start with a funny question for you. According to Google, there are about 26 Million software developers in the world. How many of them do you think would know how to create a new programming language?
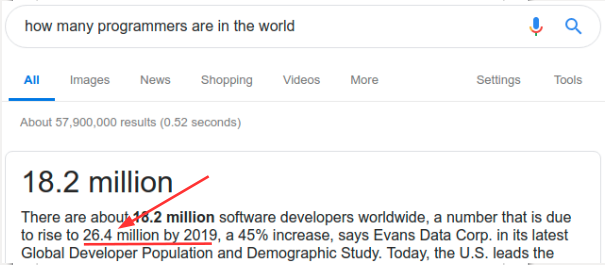
Very few of them, I bet. In fact, I didn’t receive a training about it when I was a college student.
The reason is that very few developers are real computer scientists, and even among the latter group, only few of them have studied formal languages and compilers.
Programmers are practical people: Does it compile? Does it seem to work? Okay, then push.
Few coders have been trained to think formally. Additionally, creating a programming language is a task much closer to science and art, than to pure coding (although, of course, a lot of coding is needed too).
And yet, it teaches so much! There are so many fascinating steps involved, and opportunities to learn about:
- High level software engineering,
- Advanced algorithms and data structures,
- Programming patterns,
all of which are certain to be extremely useful during the career of a developer. And a computer scientist. And a software engineer.
Steps to create a programming language
From a very high perspective, creating a new programming language involves three main steps.
- Define the grammar.
- Build the front-end compiler for the source code.
- Build the back-end code generator.
So, you start with a pen and a piece of paper where you define the Grammar of your language. If you don’t know what a Formal Grammar is, then just think about it as the grammar of a human language (and read my article about it).
For example, in a human language you might say “A sentence is made by an Article, a Noun, and a Verb”. Then, the natural ambiguity of the language, mainly given by the spoken part and by human nature, throws this rule away.
In a formal language, if your grammar says “Assignment is made by a Variable Name, the Equal (=) sign, and a Number”, then this will be the only way someone can instantiate a variable in the source code of a program, otherwise the code would not compile (or it would raise an error, in case you are building an interpreted language).
In short, the formal grammar defines what the source code of a program must look like, in this language. It’s about the syntactical rules that programmers will have to respect in order to write a program in your language.
The Front-End Compiler is a piece of software that takes the source code and produces some weird looking data structure. More about this later in the article.
Finally, the Back-End Code Generator is another piece of software that takes whatever was produced by the Front-End and creates a code that can actually be run.
Wait. That… can be run? So this is all about taking the initial source code and making a new source code (that can be run)?
Yes. But one that the machine can understand, often called Target Machine Code. Strictly speaking, it means you should provide Assembly code as a result, give it to the Assembler that will work along with the Linker/Loader and then they will give back to you the machine code.
However, many savvy people have already gone through this effort in the past. Thus, very often new programming languages are just translated into existing programming languages, for whom a compiler already exists.
For example, while architecting your new language you may decide that your compiler, instead of generating machine code, generates C code that is then given to a C compiler. This is a standard approach and it will not take away from you any of the funny parts of writing a compiler: you will still need to build one.
But then, what does writing a compiler mean? Let’s see.
Steps to create a compiler for a programming language
Building a serious compiler for a complex programming language is a hell of a task. A large team full of skilled people is needed.
For instance, it took about 3 years for the FORTRAN 1 compiler. Built for scientific computing, the FORTRAN language was a game changer in the field and it is still widely used today. They did a good job and pretty much changed the history of computing.
Despite the scary complexity, compilers have just 5 main parts:
- Lexical Analysis. Recognize language keywords, operators, constant and every token that the grammar defines.
- Parsing. The stream of tokens is “understood”, in the sense that the relation between each pair of token is encoded in a tree-like data structure. Such a tree is meant to describe the meaning of the operations, in each line of source code.
- Semantic Analysis. Probably the most obscure of all steps. Mainly involves understanding types and checking inconsistency in the “meaning” of the source code (not just in the syntax). Tough.
- Optimization. No matter how good the source code was before compilation, chances are that while going to lower levels of encoding (till machine code) several optimizations can be implemented. Things like memory optimization, or even power-consumption optimization. And, of course, runtime optimization.
- Code Generation. The optimized version of the original code is finally translated into executable code.
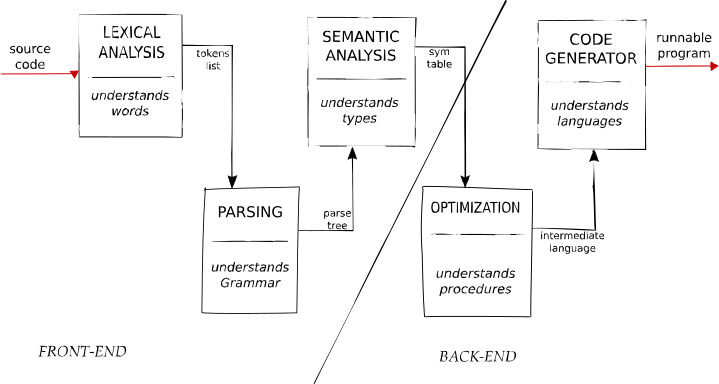
Even though these five steps to create a compiler have not changed since a few decades, the complexity and time investment devoted to each of them have changed a lot.
The first compiler for FORTRAN was built from 1954 to 1957. At that time, all steps but semantic analysis were very involved and complex, which also explains why it took 3 years to come up with the result.
Nowadays, instead, a few steps have become almost automatic. If you define your own formal grammar, and you do it well, then you can use software that makes Lexical Analysis, Parsing and Code Generation automatically for you.
Today, teams that are building and maintaining a Compiler are mostly focused around the Optimization step. It has become extremely important, especially given the big advances in hardware. The Semantic Analysis steps is also fairly involved, although not nearly as much as the Optimization.
Let’s see more details for each step.
Lexical Analysis
This step takes off directly from the Formal Grammar.
Let’s say you want to build a language to represent minimalistic arithmetic operations. Your Grammar might look like the following:
This is really a poor example, but it’s useful for the sake of illustration. You can read the above grammar as:
A Program is made by zero or more Expressions followed by a semicolon (curly brackets means “zero or more” of what’s inside them). An Expression can only be an Assignment. An Assignment is made by a Result followed by an Equal sign, followed an Operation. An Operation is made by a Variable, followed by an Operator, then another Variable. An Operator must be a symbol among four choices: “+”, “-”, “*“, “/” (double quoted symbols are terminal tokens). A Variable must be a symbol among ten choices (the ten digits). And a Result must be either the “L” symbol or the “O” symbol.
If you pause now just one minute and think, you will realize that with this silly grammar one can only represent a sequence of additions, subtractions, multiplications and divisions between 2 small integers (from 0 to 9 included). The sequence may also be empty, and if it’s not then the elements in it must be separated by a semicolon. Oh, also, the result of each operation can only be named either “L” or “O”.
A valid “source code” might look like
It’s dumb and you cannot do anything with it. But I can explain how the Lexical Analysis step works! Your Lexical Analyzer will go through the source code, and identify each token along with its type, according to the grammar. So the result of the Lexical Analyzer for the 2-liner above will be:
It should be easy to understand why there exist software tools that perform this task for any well-defined grammar. Actually, if you’ve done it manually once then it becomes boring to do it again.
Parsing
The Parser will take the list of tokens (output of the previous step) and create a tree-like structure, that is meant to describe the “meaning” of the source code. In the previous example (the silly arithmetic operations) the tree reflects the actual operations:
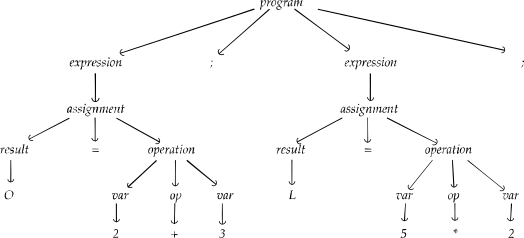
With some simplification, you can assume that the tree is not actually needed. Just knowing the leaves of the tree might be enough for the overall objective to compile the source code. At any rate, each parser may act differently but many of them do not store the actual tree in memory.
Semantic Analysis
If you are building a language with static types, or other nuances, then in this step you will want to check that the user is not doing anything stupid. Keep in mind that the user is also a programmer!
This step is very hard, in particular when it comes down to variables binding. Consider the following snippet in Python.
This is clearly not good code. But let’s look at it more closely now.
Can you imagine what a mess is for the Python interpreter to understand what you are doing by naming your variables foo, a routine foo, the argument of this routine foo and of course, using the identifier foo inside the scope of the routine called foo.
Binding is about assigning the right value (5, 7, or even an entire function body) to the right identifier ( foo , val , foo2 ), according to the current scope. Semantic analysis is about understanding if you messed up something.
Optimization
This step is a bit like editing a text after it’s been written by the original author.
However, each editor has their own objectives. So, as a code optimizer, your focus could be in reducing memory usage, or runtime. But it could also be to reduce the number of database access. Or to reduce power consumption, or network messages.
With so many specialized hardware, and so many different networks, databases, architectures, it’s no surprise that compilers can vary quite a lot how they optimize the code.
A special mention must go, in this subject, to the so-called Data Flow Optimization.
Every meaningful source code makes heavy use of aggregated data structures, such as arrays, that are accessed throughout the program. Data Flow Optimization is a term used to improve whatever the programmer did with data structures in his program, in order to make the overall execution more efficient.
Code Generation
The final step, informally named CodeGen, is also commonly automatized nowadays. In fact, translation from a parse tree to, potentially, any existing language is kind of a solved problem.
Still, there might be specific needs, or some innovation in your compiler, that convince you to build your own code generator. Most typically you would translate the parse tree either into Assembly code, or into C code that can then be compiled with an existing C compiler.
What’s next
When you complete the front-end compiler and the back-end code generator then you’re more or less ready to go. There exists a fun project on GitHub that is about creating a compiler for Lisp in every possible language (see the references at the bottom).
In my opinion, studying the theory of languages and compilers is worth the time it takes because it teaches so much about the real nature of one thing programmers use a lot: Programming Languages.
Also, it’s a good excuse to learn about parsing patterns, recursive descent algorithms, variables scope and bindings (which you should already know!). If you ever need an excuse to learn something.
As usual in engineering, the practical part is of utmost importance too. More on this in the next articles.
References
The Dragon Book. Compilers: Principles, Techniques and Tools. Wikipedia page (of the book).
Language Implementation Patterns. A book by Prof. Terrence Parr.
Alex Aiken’s class Compilers at Stanford University. Available as free MOOC online.
Creating A Programming Language From Scratch
![]()
In this article, we’ll go through the most important parts and concepts of designing a new language. We will analyze the most important points, and the logic behind them, but not the exact lines of code that make them do what they do. This way, you can follow along using the language you feel most comfortable with.
There are approximately 700 programming languages being used today by the world-wide code community. Some of them are made specifically to run on your web-browser and others are made to run on satellites that orbit the earth. With so many languages available, the question that remains is: why would we want to create a new one?
It doesn’t matter if you want to create a new language to solve a specific problem, or just to learn the inner workings of an interpreter or compiler — In both cases, you will need to understand the major steps of how source code gets translated into a set of instructions for a computer to execute.
In this article, we will go through, together, the three main steps that transform text into instructions for a machine to compute. We will do this by analyzing the theory behind each step of creating an interpreted language, using examples from the source code of the ZAP! interpreter.
The ZAP! language is a javascript interpreted language with a specific set of keywords. If you want to have a taste for the language before we begin, feel free to check out the online interpreter at https://jzsiggy.github.io/ZAP/ .
Now that you’ve had a look at what we can create, let’s dive in!
Step 1: The Lexer
The first step in creating our interpreter is to receive an input stream and separate it into tokens recognized by our language’s semantics.
A token is a data structure that transforms a string that has an underlying value to our language into something our interpreter can comprehend. The following image might make things clearer:
Как написать собственный язык программирования
Перевод статьи «Write you a programming language».
 Photo by David Schultz on Unsplash
Photo by David Schultz on Unsplash
Что это означает — написать язык? Это значит, что вам нужно написать программу, которая будет интерпретировать или компилировать язык программирования (т. е. новый язык). Но для написания этой программы вам придется использовать какой-нибудь из существующих языков (базовый язык). Также можно написать эту программу на чистом машинном коде.
Интерпретатор или компилятор?
Для начала нужно выбрать, что вы хотите написать: интерпретатор или компилятор (или оба). Какую роль они играют?
- Компьютер (машина) — это интерпретатор машинного кода (а это тоже язык, пусть и не человекочитаемый).
- Компилятор переводит исходный код на другой язык, например:
- на высокоуровневый язык программирования (транспиляция),
- на машинный код для виртуальной машины (байткод), например JVM,
- на низкоуровневый язык, например язык ассемблера, который затем будет переведен (другой программой) на машинный код.
Любопытно, что вы можете написать для своего языка программирования и интерпретатор, и компилятор. Примеры — Lisp (CommonLisp), Scheme (Chez Scheme).
Также можно написать интерпретатор или компилятор для языка программирования на этом же языке. Для этого вам придется сначала написать первый интерпретатор или компилятор на другом языке, а затем, в новых версиях, вы сможете пользоваться уже новым языком (т. н. раскрутка).
Руководства по теме создания интерпретаторов и компиляторов можно разбить на категории в соответствии с «базовыми» и «новыми» языками, например:
-
— реализация Lisp на 82 языках — реализация Scheme на Haskell — подмножество Haskell 2010, реализованное на Haskell.
Если язык реализован как компилятор, он переводит исходный язык на язык назначения. Исходный язык — то же самое, что и «новый», но язык назначения — не то же, что «базовый» язык. Руководства можно разбить по категориям в соответствии с исходным языком и языком назначения. Например:
-
. Компилятор, реализованный на Haskell, переводит язык Kaleidoscope на LLVM IR (intermediate representation, промежуточное представление кода). . Компилятор, реализованный на JS, переводит язык «λanguage» на JS. . Компилятор, реализованный на JS, переводит маленькое подмножество Lisp на C-подобный синтаксис.
Управление памятью
Следующее, что нужно определить, это как ваш язык программирования будет управлять памятью:
- вообще не будет (как, например, какой-нибудь декларативный язык)
- вам это безразлично. Выделяем память и позволяем операционной системе очищать ее после закрытия приложения.
- статическое управление памятью, как в C
- частный случай — Rust borrow checker
- частный случай — Zig
- частный случай — ссылочные возможности Pony
Система типов
Далее надо разобраться, как в вашем языке будет обстоять дело с типами:
- отсутствие типизации (когда у вас есть только один тип), пример — lambda calculus или calculator;
- динамическая типизация, пример — Lisp;
- статическая типизация, пример — Haskell;
- структурная типизация, пример — TypeScript.
Можно выбрать и кое-что позаковыристее. Например, типизацию Мартина-Лёфа (ML), зависимые типы (Idris), линейные типы и т. п.
 Photo by Alexandru Acea on Unsplash
Photo by Alexandru Acea on UnsplashПарадигмы
Все, указанное выше, касалось всех языков программирования. На следующем этапе вы можете выбрать другие особенности (одну или больше), которые определят парадигму вашего языка.
Например, вы допускаете использование функций первого класса, строгие вычисления (с вызовом по соиспользованию), динамические типы, макросы — и получаете Lisp.
- Если вы используете гигиенические макросы и продолжения, вы получаете Scheme (приблизительно).
- используя неизменяемые типы данных, вы получаете Clojure (тоже приблизительно).
Или вы можете разрешить использование функций первого класса, ленивые вычисления, статические типы — и получить на выходе ML.
Дополнительные особенности
Поверх всего этого вы можете добавить дополнительные особенности, например:
- систему модулей
- оптимизацию хвостовой рекурсии
- сопоставление с образцом, как в функциональных языках программирования, и т. п.
Генераторы парсеров
Одним из факторов успеха MAL является то, что ему не нужен генератор парсера: парсер Lisp относительно легко имплементировать. Это делает его очень портируемым (реализован более чем на 80 языках). То же касается lis.py — у него есть еще более простой токенизатор.
Большинство руководств, не связанных с Lisp, предполагают необходимость какого-то специфичного генератора парсеров, что делает их менее портируемыми.
Список туториалов
Я собрал собственную коллекцию руководств по созданию языков программирования. Они находятся в репозитории на GitHub, так что вы вполне можете стать контрибьютором.
Создаем свой язык программирования с блэкджеком и компилятором
В этом пособии с соответствующими примерами кода рассказываем о том, как написать при помощи Python свой язык программирования и компилятор к нему.
Введение
Изучение компиляторов и устройства языков программирования по видеоурокам и руководствам – дело для новичков тяжелое. В этих материалах нередко отсутствуют важные составляющие. Цель публикации – помочь людям, ищущим способ создать свой язык программирования и компилятор. Пример игрушечный, но позволит понять, с чего начать и в каком направлении двигаться.
Системные требования
Если вы незнакомы с нижеприведенными понятиями, не беспокойтесь – мы проясним необходимость этих компонентов далее, по ходу создания компилятора. В качестве лексера и парсера используется PLY. В роли низкоуровневого языка-посредника для генерации оптимизированного кода выступает LLVMlite.
Таким образом, к системе предъявляются следующие требования:
- Среда Anaconda (более простой способ для инсталляции LLVMlite – conda, а не классический pip)
- LLVMlite
- RPLY (то же, что PLY, но с более хорошим API)
-
(статический компилятор LLVM)
Свой язык программирования: с чего начать?
Начнем с того, что назовем свой язык программирования. В качестве примера он будет называться TOY. Пусть пример программы на языке TOY выглядит следующим образом:
Любой язык программирования включает множество составляющих его компонентов. Чтобы не застрять в мелочах, возьмем в качестве микропрограммы вызов одной функции нашего языка:
Как для этой однострочной программы формально описать грамматику языка? Чтобы это сделать, необходимо использовать расширенную Бэкус – Наурову форму (РБНФ) (англ. Extended Backus–Naur Form ( EBNF )). Это формальная система определения синтаксиса языка. Воплощается она при помощи метаязыка, определяющего в одном документе всевозможные грамматические конструкции. Чтобы в деталях разобраться с тем, как работает РБНФ, прочтите эту публикацию.
Создаем РБНФ (EBNF)
Создадим РБНФ, которая опишет минимальный функционал нашей микропрограммы. Начнем с операции суммирования:
Соответствующая РБНФ будет выглядеть следующим образом:
Дополним язык операцией вычитания:
В соответствующем РБНФ изменится первая строка:
Наконец, опишем функцию print:
В этом случае в РБНФ появится новая строка, описывающая работу с выражениями:
В таком ключе развивается описание грамматики языка. Как же научить компьютер транслироваться эту грамматику в бинарный исполняемый код? Для этого нужен компилятор.
Компилятор
Компилятор – это программа, переводящая текст ЯП на машинный или другие языки. Программы на TOY в этом руководстве будут компилироваться в промежуточное представление LLVM IR (IR – сокращение от Intermediate Representation) и затем в машинный язык.
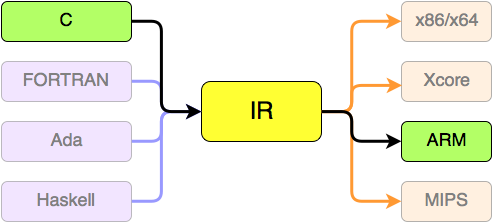
Использование LLVM позволяет оптимизировать процесс компиляции без изучения самого процесса оптимизации. У LLVM действительно хорошая библиотека для работы с компиляторами.
Наш компилятор можно разделить на три составляющие:
- лексический анализатор (лексер, англ. lexer)
- синтаксический анализатор (парсер, англ. parser)
- генератор кода
Для лексического анализатора и парсера мы будем использовать RPLY, очень близкий к PLY. Это библиотека Python с теми же лексическими и парсинговыми инструментами, но с более качественным API. Для генератора кода будем использовать LLVMLite – библиотеку Python для связывания компонентов LLVM.
1. Лексический анализатор
Итак, первый компонент компилятора – лексический анализатор. Роль этого компонента заключается в том, чтобы разделять текст программы на токены.
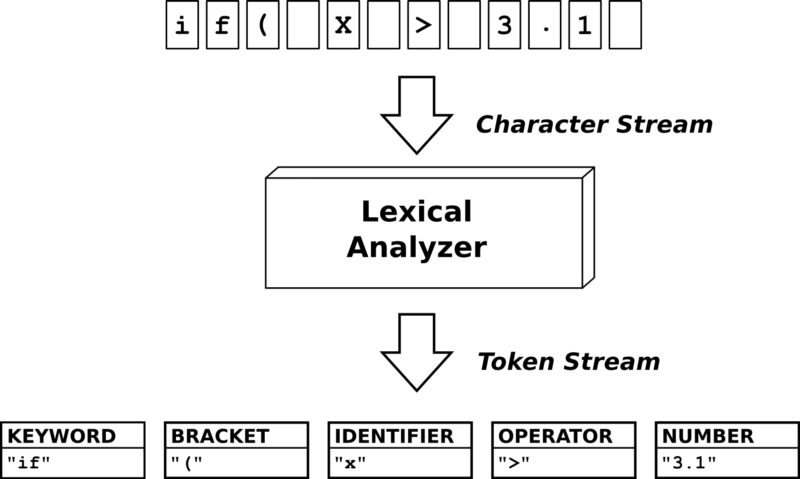
Воспользуемся последней структурой из примера для РБНФ и найдем токены. Рассмотрим команду:
Наш лексический анализатор должен разделить эту строку на следующий список токенов:
Напишем код компилятора. Для начала создадим файл lexer.py, в программном коде которого будут определяться токены. Для создания лексического анализатора воспользуемся классом LexerGenerator библиотеки RPLY.
Создадим основной файл программы main.py. В этом файле мы впоследствии объединим функционал трех компонентов компилятора. Для начала импортируем созданный нами класс Lexer и определим токены для нашей однострочной программы:
При запуске main.py мы увидим на выходе вышеописанные токены. Вы можете изменить названия своих токенов, но для простоты согласования с функциями парсера их лучше оставить как есть.
2. Синтаксический анализатор
Второй компонент компилятора – синтаксический анализатор (он же парсер). Его роль – синтаксический анализ текста программы. Данный компонент принимает список токенов на входе и создает на выходе абстрактное синтаксическое дерево (АСД). Эта концепция более трудна, чем идея списка токенов, поэтому мы настоятельно рекомендуем хотя бы по приведенным выше ссылкам изучить принципы работы парсеров и синтаксических деревьев.
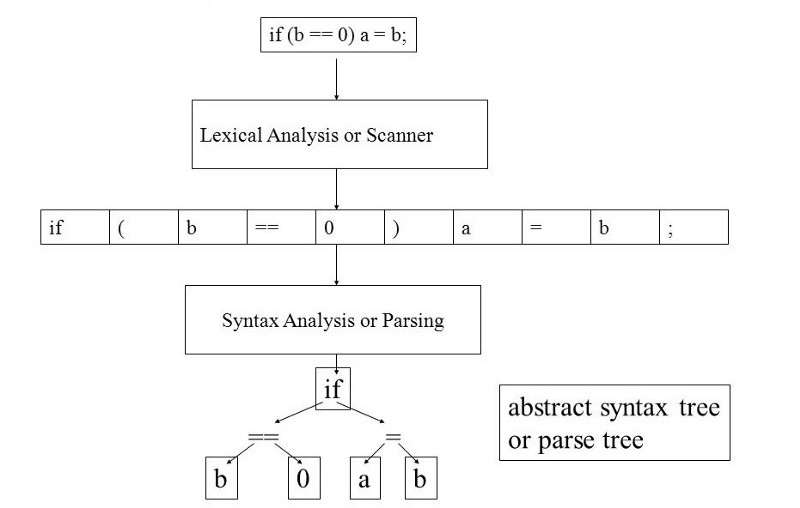
Чтобы воплотить в жизнь синтаксический анализатор, будем использовать структуру, созданную на этапе РБНФ. К счастью, анализатор RPLY использует формат, схожий с РБНФ. Самое сложное – присоединить синтаксический анализатор к АСД, но когда вы поймете идею, это действие станет действительно механическим.
Во-первых, создадим файл ast.py. Он будет содержать все классы, которые могут быть вызваны парсером, и создавать АСД.
Во-вторых, нам необходимо создать сам анализатор. Для этого в новом файле parser.py аналогично лексеру используем класс ParserGenerator из библиотеки RPLY:
Наконец, обновляем файл main.py, чтобы объединить возможности синтаксического и лексического анализаторов:
Теперь при запуске main.py мы получим значение 6. и оно действительно соответствует нашей однострочной программе «print(4 + 4 – 2);».
Таким образом, при помощи двух этих компонентов мы создали работающий компилятор, интерпретирующий язык TOY. Однако компилятор по-прежнему не создает исполняемый машинный код и не оптимизирован. Для этого мы перейдем к самой сложной части руководства – генерации кода с помощью LLVM.
3. Генератор кода
Третья и последняя часть компилятора – это генератор кода. Его роль заключается в том, чтобы преобразовывать АСД в машинный код или промежуточное представление. В нашем случае будет происходить преобразование АСД в промежуточное представление LLVM (LLVM IR).
LLVM может оказаться действительно сложным для понимания инструментом, поэтому обратите внимание на документацию LLVMlite. LLVMlite не имеет реализации для функции печати, поэтому вы должны определить собственную функцию.
Чтобы начать, создадим файл codegen.py, содержащий класс CodeGen. Этот класс отвечает за настройку LLVM и создание/сохранение IR-кода. В нем мы также объявим функцию печати.
Теперь обновим основной файл main.py, чтобы вызывать методы CodeGen:
Как вы можете видеть, для того, чтобы обработка происходила классическим образом, входная программа была вынесена в отдельный файл input.toy. Это уже больше похоже на классический компилятор. Файл input.toy содержит все ту же однострочную программу:
Еще одно изменение – передача парсеру методов module, builder и printf. Это сделано, чтобы мы могли отправить эти объекты АСД. Таким образом, для получения объектов и передачи их АСД необходимо изменить parser.py:
Наконец, самое важное. Мы должны изменить файл ast.py, чтобы получать эти объекты и создавать LLMV АСД, используя методы из библиотеки LLVMlite:
После изменений компилятор готов к преобразованию программы на языке TOY в файл промежуточного представления LLVM output.ll. Далее используем LLC для создания файла объекта output.o и GCC для получения конечного исполняемого файла:
Теперь вы можете запустить исполняем файл, для создания которого вами использовался свой язык программирования:
Следующие шаги
Мы надеемся, что после прохождения этого руководства вы разобрались в общих чертах в концепции РБНФ и трех основных составляющих компилятора. Благодаря этим знаниям вы можете создать свой язык программирования и написать оптимизированный компилятор при помощи Python. Мы призываем вас не останавливаться на достигнутом и добавить в свой язык и компилятор другие важные составляющие: